Concocter une reconnaissance vocale aux petits oignons
Comment bien pratiquer l'API Speech to Text de Google Cloud pour traiter des domaines métier spécifiques et leur jargon associé

Actuellement manager et architecte chez Niji depuis plus de 6 ans, j'ai commencé à développer des apps il y près de 10 ans, en natif pour iOS et Android. Je m'intéresse aussi bien aux évolutions des frameworks natifs qu'aux dernières technologies hybrides toujours plus performantes, mon but étant de proposer la meilleure expérience possible aux utilisateurs, quelle que soit la technologie employée !
La saisie textuelle au clavier sur nos smartphones est bien ancrée dans nos usages quotidiens, mais il existe des cas d'utilisation pour lesquels il est intéressant de proposer une alternative, telle que la dictée vocale. L'usage des assistants vocaux tels qu'Alexa, Siri, Google Assistant ou Cortana est de plus en plus courante et naturelle. La saisie vocale répond à plusieurs contraintes :
- Un côté ludique pour l'utilisateur
- Un gain de temps pour certaines professions qui y sont habituées (les médecins, les avocats etc...)
- La possibilité de dicter même avec les mains prises
Les progrès en matière de Speech To Text ont été impressionnants ces dernières années, boostés par l'avènement du Machine Learning et des modèles d'entraînement toujours plus importants. La dictée vocale est tout de même toujours un outil faillible et son intégration au sein d'un parcours fonctionnel dans une app doit être une solution alternative à une saisie clavier traditionnelle, ne serait-ce que pour des raisons d'accessibilité et de confidentialité : dicter un compte-rendu sensible en public n'est évidemment pas une bonne idée !
Nos assistants vocaux sont habitués à comprendre des ordres simples, et du vocabulaire courant ou très ciblé (notre carnet d'adresses, nos applications, nos abréviations courantes...). L'intégration d'un jargon technique ou de noms propres liés à un domaine, comme des noms de marques ou de produits commerciaux présente un challenge.
Speech API Google
Google Cloud propose une solution de Speech to text, désignée par Gartner comme l'un des leaders du secteur. Cette API présente l'avantage d'être facilement testable, et de proposer des possibilités de personnalisation importantes, elle propose de la reconnaissance en temps réel ou en asynchrone, sur de multiples langues et dispose d'options comme la ponctuation automatique ou dictée.
Exemple d'architecture de la solution
Reprenons l'exemple d'un service mobile offrant la possibilité à ses utilisateurs de dicter des notes vocales et d'en obtenir la retranscription. Ce service peut être proposé via une application iOS, Android, et un site web. Il est donc intéressant d'abstraire la communication avec l'API au travers d'un middleware pour en mutualiser la configuration. Pour ce faire, nous avons choisi de mettre en place un projet Node.js qui servira d'interface entre les clients et l'API Google. L'avantage d'utiliser un projet back entre les clients et l'API est de pouvoir également consommer des bases de données ou d'autres services pour injecter de la donnée au moment de la reconnaissance vocale.
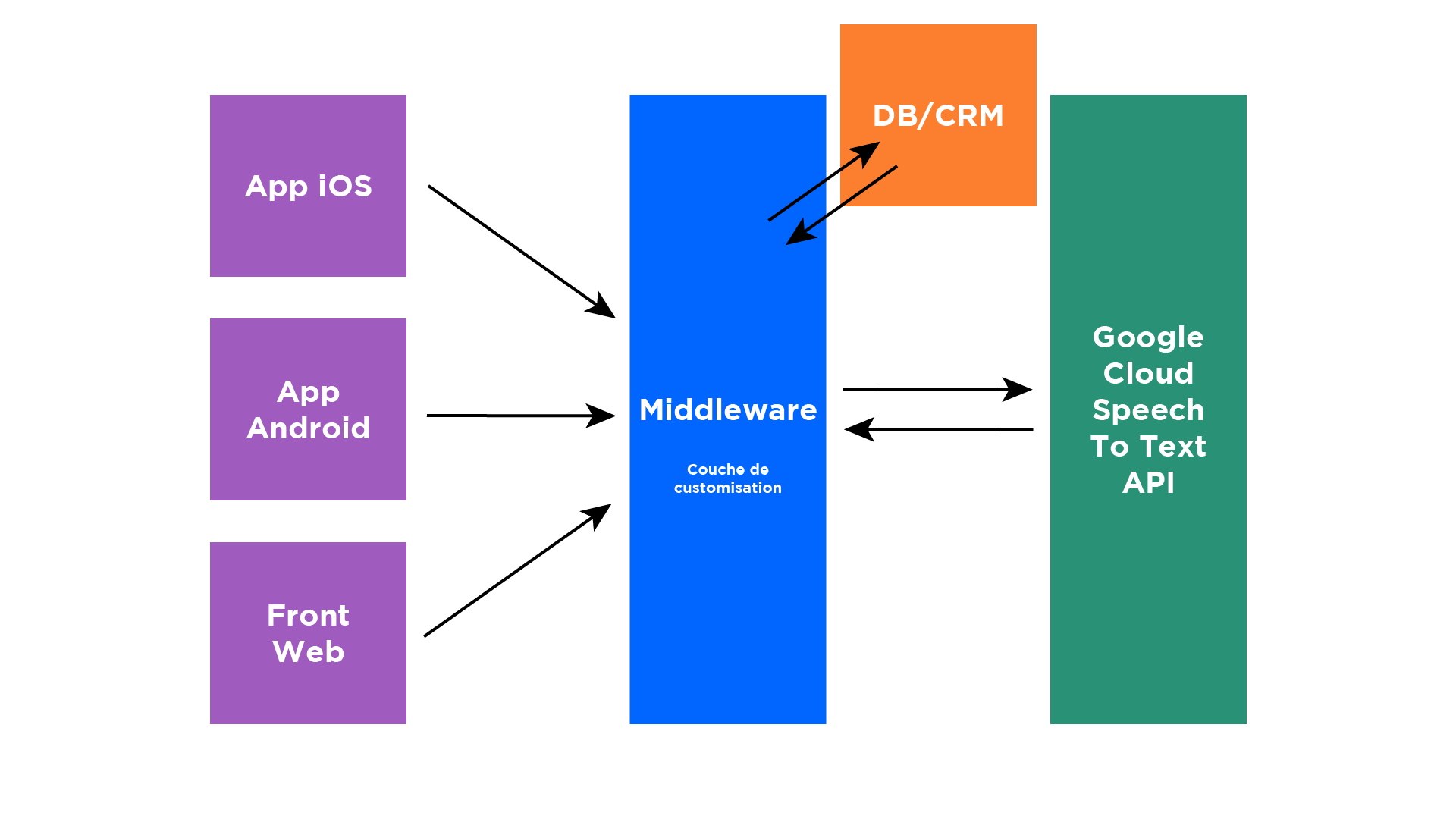
Google Cloud everywhere!
Google oblige, les différentes API Google Cloud sont interdépendantes : pour utiliser Google Speech to text API, il faut lui fournir des fichiers audio, qui doivent être stockés sur... Google Storage !
Heureusement, Google propose des SDK prêts à l'emploi dans de nombreuses technos qui facilitent grandement l'usage de ses outils : pas besoin d'écrire un wrapper sur les API REST, Google l'a déjà fait pour nous.
Pour l'hébergement du code Node.js du middleware, nous avons choisi les Cloud Functions de GCP, qui nous permettent d'avoir un modèle souple, scalable, sans avoir à gérer l'hébergement. Attention toutefois, les Cloud Functions ne gèrent pas un payload en entrée dont la taille dépasse les 10 Mo, ce qui correspond à environ 2 minutes d'audio. Pour s'affranchir de cette limite, on peut utiliser Cloud Run, solution serverless d'hébergement de conteneurs pour laquelle les payloads en entrée ne sont pas limités.
Attention également à la mémoire allouée aux Cloud Functions. Les 256 Mo par défaut peuvent s'avérer un peu justes sur des fichiers volumineux.
SpeechAdaptation
Nos premiers tests de reconnaissance vocale se sont avérés fructueux, nos phrases de test, comprenant uniquement du vocabulaire courant, étaient parfaitement reconnues. Une fois dans les mains de nos clients en revanche, ça a été la douche froide. Le jargon métier, les noms de produits, les noms propres n'étaient pas reconnus.
En suivant la documentation de Google sur l'adaptation vocale, nous avons décidé de passer sur l'API V1 Bêta, et sur les modèles améliorés de reconnaissance qui nous permettent d'injecter des modèles au moteur de reconnaissance pour améliorer les performances sur des termes peu usités ou absents des dictionnaires de référence.
Les meilleurs résultats ont été obtenus avec une combinaison des 3 solutions suivantes :
PhraseSets ou comment booster certains termes
La première piste que nous avons explorée est celle de l'injection de PhraseSets. Concrètement, l'idée est d'orienter la reconnaissance en augmentant la probabilité de reconnaissance d'un mot existant : par exemple, un mot peu usité dans le langage courant, mais qui est très souvent employé dans un contexte métier pourra être "boosté", c'est à dire qu'on va indiquer au moteur de reconnaissance que sa probabilité d'apparition dans la dictée est supérieure à ce qu'on pourrait avoir dans les modèles d'IA de Google qui sont basés sur des conversations courantes.
Dans un contexte vinicole, les mots "lies" et "moût" ont une probabilité bien plus forte d'être utilisés que dans une conversation courante. En les ajoutant aux PhraseSets, on indique au moteur de les privilégier par rapport à des mots comme "lit" ou "mou" qui sont proches en termes de phonétique.
On peut alors définir, pour chaque niveau de boost entre 1 (boost minimal) et 20 (niveau maximal) un ensemble de mots qui seront mis en avant lors de la reconnaissance.
Custom Classes ou comment apprendre du jargon nouveau
L'utilisation des PhraseSets a permis d'améliorer la qualité des transcriptions en ce qui concerne les mots existants dans la langue française, mais peu usités, cependant, pour les termes techniques, néologismes ou noms de produits, les résultats n'étaient pas concluants. L'API Speech to text propose pour ces cas là la création de Custom Classes.
Une Custom Class est un ensemble de mots qui seront ajoutés au dictionnaire du moteur de reconnaissance. Plusieurs classes peuvent être créées, regroupant plusieurs champs lexicaux. Dans notre exemple, nous avons créé une classe comprenant les noms des produits de notre client, une autre avec les noms de ses concurrents, une autre comprenant les noms de tous ses commerciaux.
Chaque classe peut enregistrer jusqu'à 1000 termes, et plusieurs classes peuvent être utilisées en simultané.
Normalisation ou la solution du dernier recours
La normalisation de termes est un nom élégant pour désigner un simple "rechercher et remplacer". En effet, le but ici est de forcer un terme lorsque le moteur de reconnaissance ne le comprend pas, malgré l'intégration de PhraseSets ou de CustomClasses.
L'inconvénient est qu'une fois qu'un terme est normalisé, il devient alors impossible de le dicter, il sera toujours automatiquement remplacé. Un exemple de normalisation utile est la gestion d'unités de mesures : par exemple, normaliser "degrés" en "°C", ou "grammes par litre" en "g/L".
En résumé
L'utilisation de SpeechAdaptation permet de grandement améliorer les performances du moteur de reconnaissance sur un jargon métier spécifique. Pour déterminer quelle solution utiliser entre PhraseSet, Custom Class ou Transcript Normalization, le process est le suivant :
- Si le mot/terme à reconnaître existe dans la langue cible, alors on privilégie le boost via les
PhraseSetpour augmenter la probabilité de reconnaissance face à des termes proches phonétiquement, mais plus usités. - Si le mot/terme n'existe pas, alors on l'ajoute via une
Custom Classpour étendre le dictionnaire du moteur. - Si aucune solution ne fonctionne, alors on peut envisager la normalisation, en étant conscient qu'il s'agit d'une solution de dernier recours. On peut également l'utiliser pour forcer l'utilisation de symboles ("euros" => € etc...)
Limites
Le paramétrage de SpeechAdaptation n'est pas sans conséquences sur les temps de calcul du moteur de reconnaissance. Plus on injecte de données, plus le temps de calcul sera long. Pour une dictée d'environ 1 minute, avec plusieurs dizaines de PhraseSet et plusieurs milliers de termes sur les Custom Classes, la reconnaissance prend environ 15 secondes, ce qui n'est pas négligeable, en plus du temps d'envoi du fichier audio sur le réseau.
Une autre limitation est l'impossibilité (à l'heure actuelle du moins) d'injecter un mot ainsi que sa prononciation associée. Dans le cas d'un anglicisme ou d'une prononciation particulière, on peut continuer d'avoir des erreurs de reconnaissance malgré la SpeechAdaptation.
Protocole de test
Lors de nos différents tests sur les possibilités de la Speech Adaptation, nous avons eu besoin d'avoir un protocole de test reproductible afin de vérifier les variations de performances. Pour ce faire, nous avons enregistré des fichiers audio sur un ensemble de phrases représentatives du vocabulaire à reconnaître.
Via un script, on peut alors rejouer ces enregistrements et s'assurer que seuls les changements apportés à la configuration auront une influence sur la transcription, et non un écart lors de plusieurs dictées successives d'une même phrase.
Ce script nous retourne un fichier CSV avec pour chaque fichier, la transcription associée.
Pour comparer les différents tirs de test, nous avons utilisé SCTK, un outil de scoring qui permet de comparer des chaînes de caractères.
Une fois le repo cloné localement, il faut lancer la commande suivante :
sclite -i wsj -r ./monFichierDeReference.csv -h ./monFichierAComparer.csv
Pour obtenir instantanément le bilan indiquant le pourcentage de mots correctement reconnus (Corr), ceux ayant disparu (Del), ceux étant apparus (Ins), et le taux d'erreur (Err).
Attention il s'agit de nuancer ces résultats puisque l'utilisation des Custom Classes ou de la normalisation peuvent augmenter le taux d'erreur (kilomètre-heure dans la référence, km/h dans l'enregistrement).
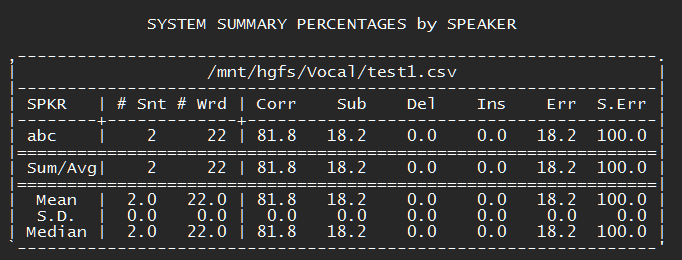
Un outil comme FileMerge (Mac) ou WinMerge (Windows) permet également de mettre en surbrillance les différences et de les mettre en évidence pour comparer rapidement 2 exécutions du script.
Conclusion
Dans un système dont nous ne maîtrisons pas l'apprentissage, on peut multiplier les tests sans en améliorer la capacité à bien répondre. Ainsi, concernant le vocal, chaque test comporte sa part de bruit (bruit de fond, qualité du micro et du réseau, hésitations, ambigüités, accents etc.) rendant ainsi le résultat non prédictible. Google offre une panoplie d'outils permettant de mieux adapter l'algorithme au contexte, mais la retranscription parfaite en toute circonstances n'est pas pour demain. Dès lors, la reconnaissance vocale reste une assistance à la saisie et il peut être périlleux d'en attendre trop ("OK Google, freine avant le rond-point"). Trop parce que notre voix est faillible, et c'est d'ailleurs l'une des raisons qui poussent certains à tenter de reconnaître les émotions par la voix. Le frein devient alors un atout (rapport au rond-point), et débloque de nouvelles expériences pour l'utilisateur toujours plus ému.