Introduction à l'Intelligence Artificielle
“Hands-on” Régression Linéaire Simple

Comme cela arrive souvent de nos jours, dès qu'une nouvelle technologie émerge, tout le monde commence à en parler partout et elle devient omniprésente dans les médias, la publicité et même dans nos conversations occasionnelles.
Je me demande si, la prochaine fois que nous irons acheter une cafetière ou un rasoir électrique, le vendeur nous dira qu'il est équipé de l'IA (sans évidemment avoir lui-même une idée de ce dont il parle).

Peut-être est-ce ce buzz qui vous pousse à lire ces lignes, ou bien vous avez décidé de vous plonger dans le monde magique de l'IA. Dans les deux cas, cet article cherchera à vous donner un aperçu de l'une des nombreuses disciplines qui la composent.
Nous nous concentrerons en effet sur ce qui est appelé l'apprentissage automatique (Machine Learning) à travers une rapide introduction à la théorie et à l'intuition qui se cachent derrière, puis nous les appliquerons à un simple exemple pratique.
Définition de l'Intelligence Artificielle

Le terme intelligence artificielle (IA), attribué à McCarthy qui l'a utilisé pour la première fois lors d'une conférence en 1956, englobe un ensemble de disciplines telles que l'apprentissage automatique, la reconnaissance vocale, la vision artificielle, le traitement du langage naturel, la robotique et l'analyse des big data. Ces disciplines sont déjà utilisées dans de nombreux secteurs de notre société et continuent d'intégrer de plus en plus notre quotidien (que nous le voulions ou non).
Cependant, ce n'est que ces dernières décennies que la puissance des ordinateurs a permis à l'intelligence artificielle de progresser à un rythme sans précédent. En effet, la capacité à traiter d'énormes quantités de données en peu de temps a permis le développement de nouvelles techniques et domaines, qui continuent à se perfectionner.
La figure suivante présente les différentes catégories d'algorithmes et de méthodologies qui composent l'IA ainsi que leurs relations d'inclusion.
Comme mentionné précédemment, nous concentrerons notre attention sur ce qui est communément appelé le Machine Learning (ML).
Le Machine Learning
Le ML est un domaine de l'intelligence artificielle qui se consacre au développement et à l'analyse d'algorithmes statistiques capables d'apprendre à partir de données et de généraliser des données non vues auparavant.
Ces algorithmes, une fois leur apprentissage terminé, sont capables de prédire des valeurs et de trouver des solutions sans intervention humaine supplémentaire.
Dans cette figure, nous pouvons voir une classification des algorithmes basée sur le mode d'apprentissage.

Supervised Learning (apprentissage supervisé)
Nous parlons d'apprentissage supervisé lorsque l'algorithme se base sur des observations existantes - déjà associées à un résultat - et les utilise pour déterminer (prédire) la valeur d'une nouvelle observation.
Avec cette technique, nous pouvons prédire une valeur numérique (comme par exemple le prix d'une maison dans une région donnée), ou bien placer la nouvelle observation parmi un nombre prédéterminé de résultats possibles (par exemple, décider si un e-mail est un spam ou non).
Dans le premier cas, nous parlons de Régression, tandis que dans le second, il s'agit de Classification. Dans les deux cas, une première phase d'entraînement du modèle est nécessaire, réalisée avec un grand nombre de données en entrée.

Unsupervised Learning (apprentissage non supervisé)
Comme le nom l'indique, dans ce cas, l'entraînement avec des observations existantes n'existe pas. C'est l'algorithme qui trouve des similitudes entre les données et fournit une classification en fonction de celles-ci.
La figure ci-dessous présente un exemple de Clustering.
Imaginons avoir des données brutes comme dans l'image à gauche. Le système regroupe les différents symptômes en trois catégories distinctes (à droite) représentées graphiquement par des couleurs.

Reinforcement Learning (apprentissage par renforcement)
Dans cette discipline, c'est le système lui-même qui 'apprend' de ses erreurs ou de ses réussites en se basant sur le résultat des actions précédentes, sans nécessité d'intervention humaine.

C'est l'une des plus fascinantes de toute l'IA (elle fait partie du Deep Learning) car elle est peut-être celle qui se rapproche le plus de la définition de l'Intelligence Générale. Ses applications vont des jeux vidéo aux voitures autonomes et à la robotique.
Ci-dessous nous chercherons à appliquer un des ces algorithmes à un exemple pratique. Puis nous entrerons progressivement dans les détails jusqu'à implémenter notre premier modèle avec le langage python et Google Colab, un outil de développement cloud adapté à l'apprentissage qui ne nécessite aucune configuration ni installation.
Étude de cas : Fête de la Raclette

Vous faites partie des organisateurs de la 9e fête de la raclette de votre village, et votre tâche est de fournir les pommes de terre.
C'est la première fois que vous le faites, et vous ne savez pas combien vous devrez en acheter, mais une chose est sûre : vous voulez éviter tout gaspillage !
Heureusement pour vous, le maire vient à votre aide et vous remet un billet avec des informations sur les fêtes des années précédentes. Dans ce billet, vous pouvez trouver combien de kilos de fromage ont été utilisés et combien de pommes de terre ont été effectivement consommées année après année.
| Année | Fromage (Kg) | Pommes de terre (Kg) |
| 2015 | 32.0 | 34.2 |
| 2016 | 31.0 | 33.1 |
| 2017 | 36.0 | 35.7 |
| 2018 | 33.4 | 34.8 |
| 2019 | 32.8 | 34.7 |
| 2020 | 37.9 | 36.0 |
| 2021 | 36.1 | 36.5 |
| 2022 | 34.8 | 35.0 |
| 2023 | 33.1 | 34.4 |
| 2024 | 37,5 | ? |
Vous savez que cette année, 37,5 kg de fromage ont été achetés pour la fête.
Pour commencer, divisons notre tableau en deux parties (on utilise X et y pour les listes de valeurs selon la convention):
kg de fromage, variable indépendante
X = [32.0, 31.0, 36.0, 33.4, 32.8, 37.9, 36.1, 34.8, 33.1]
kg de pommes de terre, variable dépendante.
y = [34.2, 33.1, 35.7, 34.8, 34.7, 36.0, 36.5, 35.0, 34.4]
Traçons-les sur un graphique.
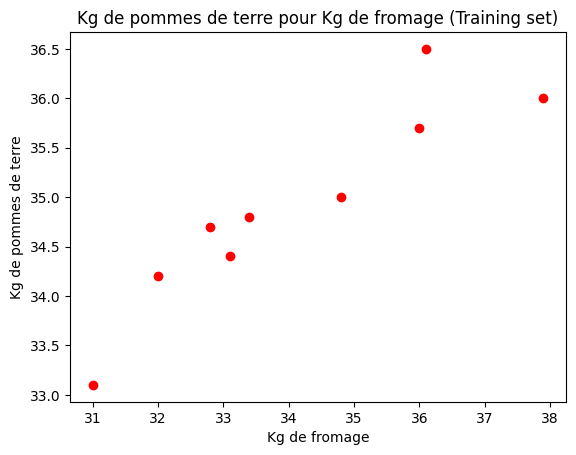
Simple Linear Regression
La régression linéaire simple (SLR) est utilisée pour estimer la relation entre deux variables quantitatives. Elle permet de "prédire" la valeur d'une variable dépendante (dans notre cas les kilos de pommes de terre) en fonction de la valeur de la variable indépendante (kilos de fromage).
La SLR est la technique d'apprentissage automatique (supervisé) la plus simple et la plus économique, ce qui explique pourquoi elle est aussi la plus utilisée et souvent la plus efficace.
Intuition sous-jacente
L'intuition derrière cette idée est de trouver la droite (fonction linéaire) qui s'ajuste le mieux aux données représentées dans le diagramme.
Essayons de deviner la meilleure droite et de la tracer sur le graphique :

Sur la figure, nous pouvons voir que notre droite passe près de certains points et plus loin pour d'autres. C'est normal, nous remarquons une différence entre les données prédites par la fonction et les données réelles, car en général, il n'est pas possible de faire correspondre parfaitement tous les points.
Les points qui composent la droite sont les valeurs prédites et sont généralement notés ŷ (rappelons que le vecteur des valeurs observées est appelé y).
La formule qui décrit cette fonction est la suivante :

Exemple:
Pour l'année 2020 l'estimation est calculée comme suit :
$$\displaylines{ \hat y_5 = a + b * x_5 \\ \downarrow \\ \hat y_5 = a + b * 37.9 }$$
En faisant varier a et b, la ligne change de point de départ et d'inclinaison. En jouant avec ces deux paramètres, nous pouvons trouver la « meilleure » des droites.
Mais comment savons-nous laquelle est la meilleure ?
Nous devons trouver a et b de manière à ce que la somme de toutes les erreurs soit minimale. Définissons donc une « fonction coût » qui nous guidera dans le choix des coefficients.
La plus courante est la MSE (erreur quadratique moyenne) :
$$\LARGE{} \frac{\sum_{i=0}^n (y_i - \hat y_i)^2}n$$
La technique est donc relativement simple : nous additionnons toutes les erreurs jusqu'à ce que nous trouvions des valeurs pour a et b telles que cette somme soit la plus faible !
Vous pouvez essayer de faire le calcul à la main, mais même avec ces quelques valeurs, cela vous prendra probablement un peu de temps !
La solution la plus pratique est de prendre votre éditeur Python préféré et d'exécuter le code suivant (testé sur Google Colab pour sa facilité d'utilisation).
Exemple pratique (hands-on)
Le langage de programmation le plus répandu dans le domaine de la recherche et du développement de systèmes d'intelligence artificielle est actuellement Python.
Dans le code suivant, il est possible de revoir la technique que nous avons présentée de manière théorique et ainsi générer un modèle.
# importons les bibliothèques dont nous avons besoin
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Créons les deux tableaux avec les données.
# Kg fromage
X = np.array([32.0, 31.0, 36.0, 33.4, 32.8, 37.9, 36.1, 34.8, 33.1]).reshape(-1, 1)
# Kg pommes de terre
y = np.array([34.2, 33.1, 35.7, 34.8, 34.7, 36.0, 36.5, 35.0, 34.4])
Maintenant, nous pouvons utiliser la puissante bibliothèque scikit-learn pour créer notre modèle et l'entraîner (training) sur nos vecteurs X et y.
# importons et créons le modèle pour la régression linéaire
from sklearn.linear_model import LinearRegression
# 'regressor' est notre modèle
regressor = LinearRegression()
# la méthode fit() effectue l'entraînement sur les données
regressor.fit(X, y)
Notre modèle est maintenant prêt ! Nous pouvons tout d'abord l'utiliser pour générer le graphique en utilisant la méthode predict() qui, pour chaque point de X, nous donnera la valeur prédite correspondante.
# plot
plt.scatter(X, y, color = 'red')
plt.plot(X, regressor.predict(X), color = 'blue')
plt.title('Kg de pommes de terre pour Kg de fromage (Training set)')
plt.xlabel('Kg de fromage')
plt.ylabel('Kg de pommes de terre')
plt.show()

Voilà les coefficients a et b qu'il a générés
# montrons l'intercept a
print("a : " , regressor.intercept_)
a = 20.469411666014203
# montrons le coefficient b
print("b : " , regressor.coef_)
b = 0.42388569
Résultat
Nous sommes arrivés à la fin de notre voyage dans la SLR et nous pouvons maintenant utiliser notre modèle pour savoir combien de pommes de terre nous devons acheter pour la fête de cette année.
Il suffit d'appliquer les coefficients à notre formule
$$\hat y_9 = 20.469411666014203 + 0.42388569 * 37.5$$
Mais laissons notre modèle faire le calcul :
# Appliquons la méthode predict à notre quantité de fromage.
print("prédiction : ", regressor.predict([[37.5]]))
Prédiction : 36.3
Félicitations ! Vous savez enfin combien de kilos de pommes de terre vous devrez acheter pour la fête (et pas de gaspillage !)
Attention cependant ! Ne jetez pas votre modèle, il pourra vous être utile pour la prochaine fête de la raclette, gardez-le toujours avec vous.

Conclusion
Nous avons pris un aperçu global de ce qui constitue l'IA, nous avons examiné plus en détail ce qu'est le ML et quelles en sont les composantes. Enfin, nous avons étudié ensemble un cas pratique et appliqué (avec succès) l'un des algorithmes de base de l'apprentissage supervisé.
Si vous avez été passionnés (et amusés) comme moi par cette première aventure dans le monde du ML, alors (comme moi) vous serez impatients de découvrir ce que la suite de cette série sur l'IA nous réserve. Nous continuerons à explorer les différentes techniques et la théorie, le tout avec des exemples "hands-on".
Je vous attends pour le prochain épisode, et d'ici là : bon apprentissage (automatique) !