Introduction à la sécurité d’un cluster Kubernetes (1/2)

Kubernetes est une technologie d’orchestration de conteneurs, aussi efficace que complexe à maîtriser. Après un déploiement, le cluster est parfois laissé en l’état, sans mesures de sécurité concrètes ni dispositifs de prévention des risques. Cependant, l’absence de sécurisation peut avoir des conséquences dramatiques, pouvant dans les pires cas permettre à un attaquant de prendre le contrôle du cluster, voire de se latéraliser sur le réseau interne de l’entreprise.
Dans ce premier article consacré à la présentation d’un cluster Kubernetes sous le prisme de la cybersécurité, nous commençons par décrire son architecture globale afin de mieux comprendre les enjeux de sécurité qui y sont liés. L’objectif est d’apporter une compréhension générale du fonctionnement du cluster, avec une mise en avant des composants présentant les risques et enjeux principaux.
Architecture d’un cluster Kubernetes
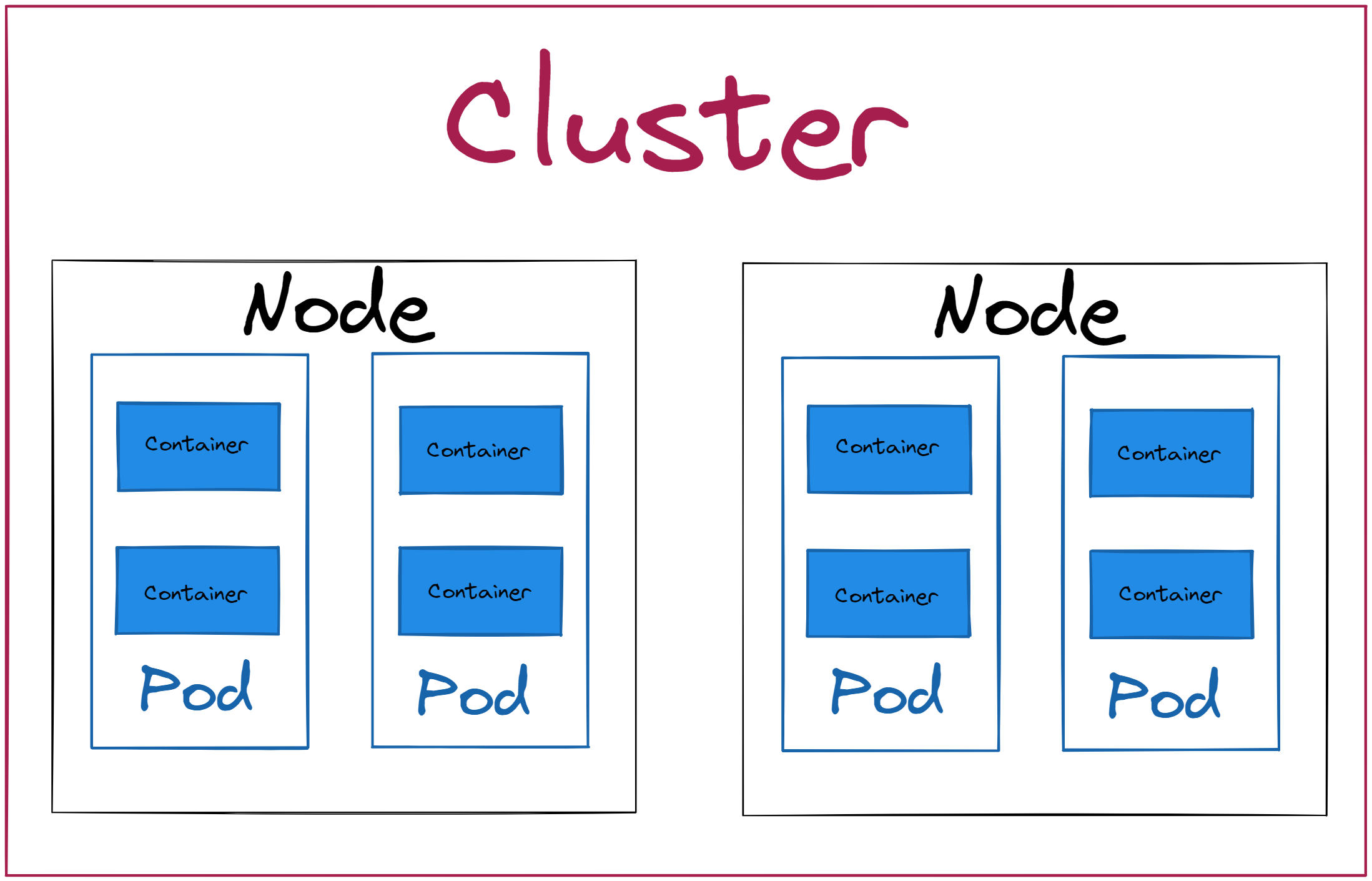
Bien que complexe, un cluster Kubernetes peut tout de même se résumer à un groupe de machines qui travaillent ensemble pour exécuter des applications. Chaque machine s’appelle un nœud.
Kubernetes organise ces nœuds en deux rôles principaux :
🧠 Le nœud maître (ou master node) porte le plan de contrôle. Celui-ci pilote le cluster. Il expose l’API, décide où lancer les applications et garde la vue d’ensemble de l’état du cluster.
👷 Le nœud de travail (ou worker node). Il exécute les applications et héberge les pods. Il suit les instructions du master, puis lui remonte ce qui se passe.
Chaque nœud peut correspondre à une machine physique ou virtuelle. Généralement, un cluster comprend au moins un nœud maître et plusieurs nœuds de travail. En production, on utilise souvent plusieurs nœuds maîtres, typiquement trois, pour la haute disponibilité. Le nombre de nœuds de travail est variable et peut s’ajuster selon la charge.
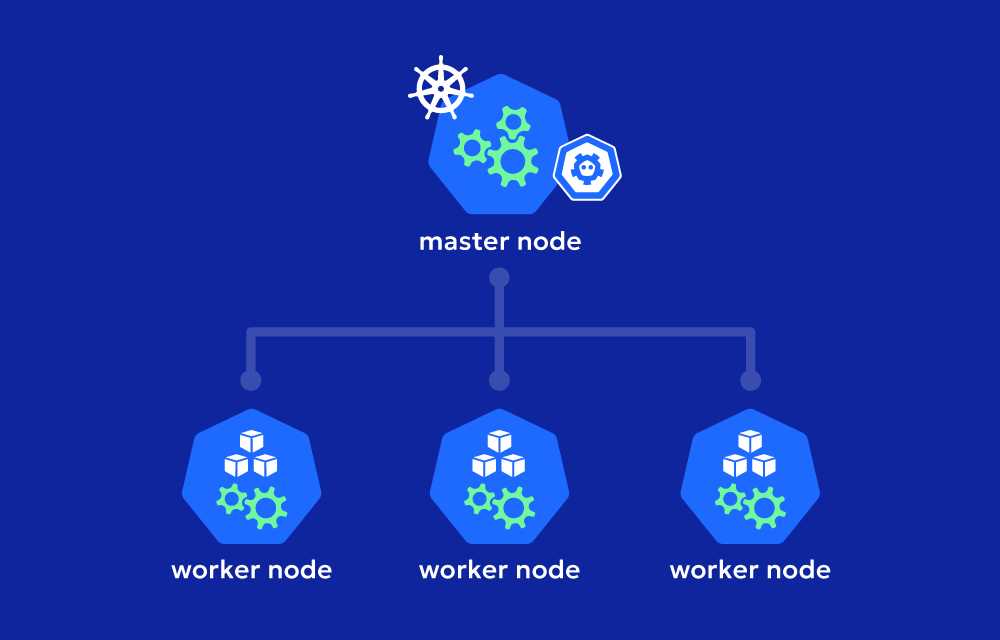
Ces nœuds, qu’ils soient des machines physiques ou virtuelles, ainsi que le réseau et le stockage, constituent la couche matérielle du cluster.
Par-dessus vient la couche logique Kubernetes. Elle transforme cet ensemble en une plateforme unique qui orchestre le déploiement des applications, leur mise à l’échelle, leur redémarrage en cas de panne et la communication entre eux.
Nœud maître (ou master node)
Le nœud maître porte le plan de contrôle. Il expose l’API permettant de contacter et récupérer des informations sur le cluster Kubernetes, garde l’état du cluster, décide où exécuter les applications et s’assure que ce qui tourne correspond à ce qui est demandé.
Pour déployer un cluster Kubernetes, il est nécessaire de choisir une distribution Kubernetes (k3s, RKE2, etc.). Elles se distinguent surtout par le mode d’installation et de gestion, le stockage de l’état, les composants fournis par défaut, le niveau de durcissement et la façon de mettre à jour.
Malgré ces variations, on retrouve les mêmes briques au sein du plan de contrôle.
🌐 Serveur d’API (kube-apiserver) : point d’entrée du cluster, il gère l’authentification, l’autorisation et la validation des requêtes. On peut joindre cette API depuis une machine de développement / gestion hors du cluster avec l’outil « kubectl ». C’est par cette API que l’on administre l’ensemble du cluster.
🛢 Magasin d’état : base de données sous forme « clé-valeur », qui conserve l’état du cluster (le plus souvent etcd). Il peut être hébergé sur les nœuds maîtres ou externalisé sur des machines séparées.
📝 Planificateur (kube-scheduler) : choisit sur quels nœuds exécuter les applications selon les ressources et contraintes.
🔄 Gestionnaires de contrôleurs (kube-controller-manager et éventuellement cloud-controller-manager) : surveillent l’écart entre l’état voulu et l’état réel et déclenchent les actions nécessaires.
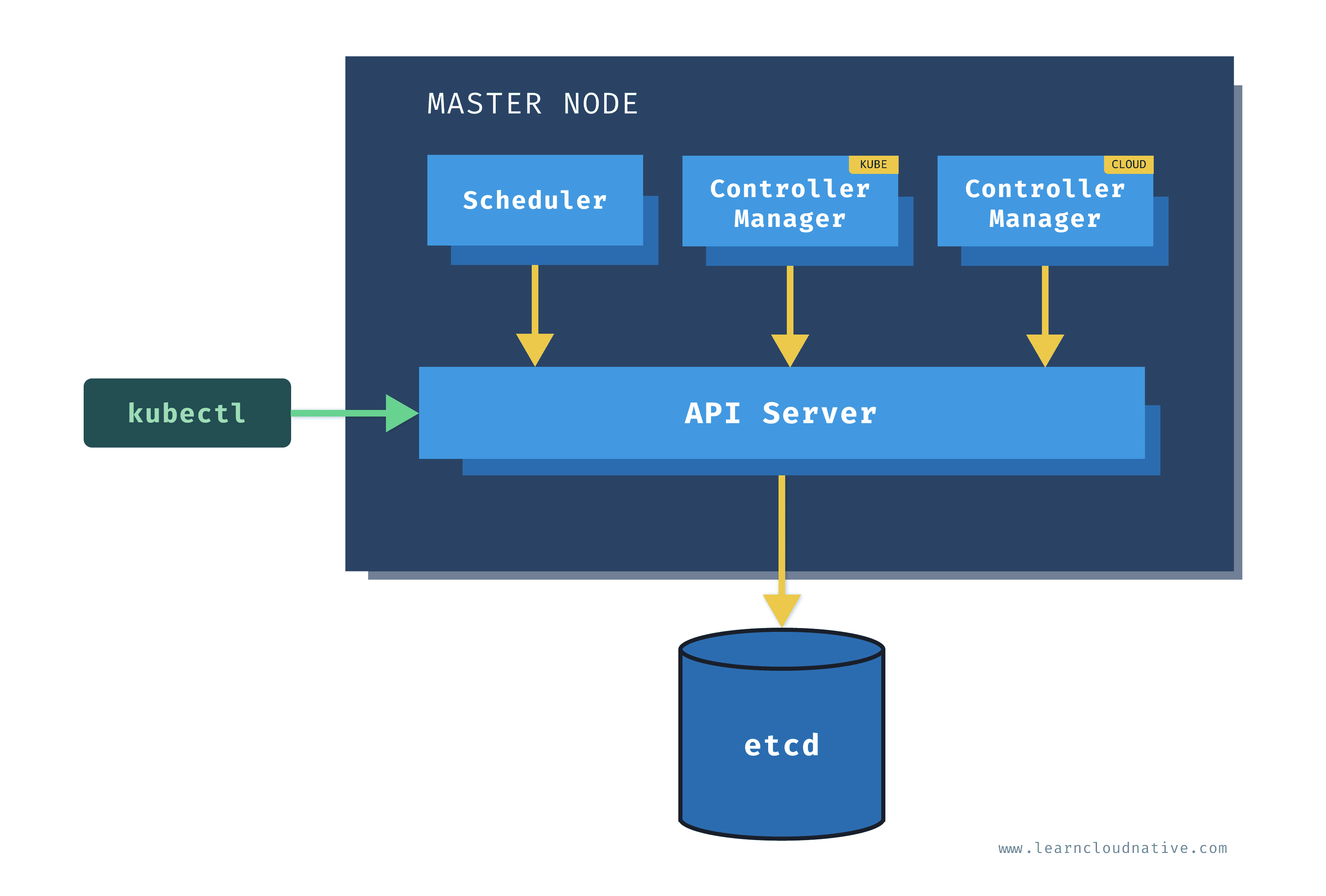
Le rôle de ces briques est le même partout : seules les technologies, l’assemblage et la configuration varient, selon la distribution. Ces éléments forment le plan de contrôle, qui est le cerveau du cluster.
Nœud de travail (ou worker node)
Le nœud de travail exécute les applications. Il s’appuie sur les ressources de sa machine physique ou virtuelle (CPU, GPU éventuels, mémoire RAM, réseau et stockage local). Il applique les décisions du plan de contrôle et remonte son état.
Encore une fois selon la distribution, la mise en place varie, mais on retrouve les mêmes briques.
☁️ kubelet : agent du nœud qui reçoit les ordres du plan de contrôle, lance les applications et vérifie leur bon fonctionnement.
📶 proxy (kube-proxy ou équivalent eBPF) : met en place le routage et la traduction nécessaires aux services.
🏗️ Runtime de conteneur : le moteur qui lance et arrête les conteneurs. Typiquement containerd, utilisé aussi par Docker, ou CRI-O, conçu pour Kubernetes.

D’autres composants peuvent aussi être présents, par exemple des plugins CSI pour le stockage, ainsi que des agents de logs et de métriques. Nous n’entrerons pas dans ces détails ici.
⚠️ À noter : un nœud maître peut parfois également être un nœud de travail. Bien que cela ne soit pas du tout recommandé d’un point de vue sécurité, c’est parfois le cas.
Pods
Un pod Kubernetes regroupe un ou plusieurs conteneurs étroitement liés. C’est la plus petite unité déployable et gérable dans Kubernetes. Contrairement aux nœuds, qui sont des machines physiques ou virtuelles, un pod n’a pas d’existence matérielle. Le nœud maître choisit un nœud de travail sur lequel l’exécuter et en supervise le fonctionnement. Les conteneurs d’un même pod partagent la même adresse IP, des volumes de stockage et le même cycle de vie.
On peut l’assimiler à un petit groupe de conteneurs qui doivent toujours démarrer ensemble, ce qui se rapproche d’un usage simple de docker-compose sans en être l’équivalent exact.
Dans la pratique, on déploie rarement des pods seuls. On passe par un objet Kubernetes « Deployment » qui décrit l’état voulu de l’application et orchestre la création et la mise à jour des pods ainsi que les ressources associées. Nous y reviendrons plus loin dans l’article.
TL;DR - En résumé
Un nœud est une machine physique ou virtuelle. Un nœud peut héberger plusieurs pods. Un pod regroupe un ou plusieurs conteneurs qui partagent la même adresse IP et des volumes.
Le nœud maître pilote le plan de contrôle. Il expose l’API, maintient l’état et décide où placer les applications. Les nœuds de travail exécutent ces décisions et fournissent CPU, mémoire, réseau et stockage.
Objets Kubernetes
Après avoir présenté l’architecture d’un cluster, il est temps d’aborder la couche logique que Kubernetes met en place pour mobiliser les ressources.
Dans Kubernetes, tout est objet. L’état voulu d’un objet est décrit dans un fichier YAML appelé manifeste. Dans un manifeste YAML, on indique l’objet à créer avec l’attribut kind. Le reste du manifeste décrit la configuration de cet objet.
Depuis la machine de l’utilisateur, il est alors possible d’utiliser l’outil kubectl pour contacter le serveur d’API (kube-apiserver) du plan de contrôle et lui soumettre les manifestes décrivant les objets à créer ou à modifier dans le cluster.

Le serveur d’API enregistre ces objets et les fait persister. Les contrôleurs du plan de contrôle (kube-controller-manager et éventuellement cloud-controller-manager) comparent en continu l’état voulu et l’état réel, puis déclenchent les actions nécessaires. Ainsi, CPU, mémoire, réseau et stockage peuvent être pilotés sans intervenir directement sur les machines.
Dans cette partie, nous allons aborder les objets les plus utiles et sensibles côté sécurité.
Deployments
Le Deployment est un objet prévu pour décrire l’état voulu d’un groupe de pods identiques et Kubernetes crée puis remplace ces pods pour respecter cet état. Un Deployment peut déclarer ou référencer d’autres ressources de l’écosystème Kubernetes avec lesquelles ce groupe de pods interagit.
Cet objet ne contient pas les autres ressources comme les Secrets, volumes ou Services. Il les référence pour que les pods puissent les utiliser, ces ressources étant définies séparément. En revanche, les pods qu’il lance lui appartiennent et il veille à en maintenir le nombre demandé.
Prenons un cas d’exemple d’un manifeste YAML décrivant un objet Deployment simple.
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: web
image: nginx:1.25
ports:
- containerPort: 80
env:
- name: DB_USER
valueFrom:
secretKeyRef:
name: app-secret
key: DB_USER
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: app-secret
key: DB_PASSWORD
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
persistentVolumeClaim:
claimName: web-data
Ce manifeste définit un Deployment nommé web. Il crée deux pods identiques (replicas 2) étiquetés app=web, qui exécutent l’image nginx:1.25 et exposent le port 80 du conteneur.
Les variables d’environnement DB_USER et DB_PASSWORD sont lues depuis un Secret nommé app-secret, stocké dans le cluster. Ce Secret est défini dans un autre manifeste YAML.
Également, le répertoire /data du conteneur est monté depuis un volume persistant qui est également un objet Kubernetes de type « PersistentVolumeClaim », défini dans un autre manifeste YAML .
Il est alors possible de déployer l’ensemble de ces objets dans le cluster pour mettre l’application en service. L’outil « kubectl », installé sur une machine externe au cluster et correctement configuré, envoie les manifestes YAML au serveur d’API du plan de contrôle qui les enregistre et déclenche leur création.
# Déploiement des objets depuis le fichier YAML
$ kubectl apply -f web-deploy.yaml
secret/app-secret created
persistentvolumeclaim/web-data created
deployment.apps/web created
# Vérifier le déploiement
$ kubectl get deploy web
NAME READY UP-TO-DATE AVAILABLE AGE
web 2/2 2 2 25s
# Vérifier les pods créés par le Deployment
$ kubectl get pods -l app=web
NAME READY STATUS RESTARTS AGE
web-7c89f4d64c-4xq9t 1/1 Running 0 22s
web-7c89f4d64c-bp5km 1/1 Running 0 22s
# Vérifier le volume persistant réclamé (PVC)
$ kubectl get pvc web-data
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
web-data Bound pvc-1a2b3c4d-5678-90ab-cdef-112233445566 1Gi RWO standard 30s
# Vérifier le Secret
$ kubectl get secret app-secret
NAME TYPE DATA AGE
app-secret Opaque 2 34s
Comme il est possible de le constater, trois objets ont bien été créés dans le cluster : un Deployment, un PersistentVolumeClaim (stockage persistant) et un Secret, même si les deux derniers n’étaient pas montrés en YAML.
Avec la commande kubectl get, il est possible de lister leur état et de vérifier que le Deployment est prêt, que le PersistentVolumeClaim est lié à un volume et que le Secret est présent. Il est aussi possible de voir que les 2 pods rattachés au Deployment sont en exécution, conformément au nombre de réplicas demandé.
ℹ️ Information : Il est en soi possible de créer un pod unique qui contient ses conteneurs. Ce pod fonctionnerait, mais il resterait limité dans l’écosystème Kubernetes. Il ne bénéficierait pas pleinement des mises à jour contrôlées, de la reprise automatique en cas de panne, de l’augmentation du nombre d’instances ni d’une intégration avec le stockage persistant, la configuration réseau ou les secrets.
Secrets
Un Secret est un objet Kubernetes pour stocker des données sensibles comme des mots de passe, des clés ou des tokens. Il est stocké dans le magasin d’état du cluster, souvent etcd (comme tous les objets du cluster). Dans l’objet tel qu’il est stocké dans le cluster et renvoyé par l’API, les valeurs sont encodées en base64. Dans un manifeste local, il est possible de les écrire en clair et Kubernetes fera l’encodage, ou bien les fournir déjà encodées.
Exemple d’un manifeste local :
apiVersion: v1
kind: Secret
metadata:
name: app-secret
type: Opaque
stringData:
DB_USER: app
DB_PASSWORD: s3cr3t
Après le déploiement de ce Secret dans le cluster Kubernetes, il est possible d’en récupérer les valeurs avec « kubectl ». Elles sont renvoyées encodées en base64 par l’API du plan de contrôle et peuvent être décodées si besoin.
# Lister
$ kubectl get secret app-secret
NAME TYPE DATA AGE
app-secret Opaque 2 34s
# Voir le contenu encodé
$ kubectl get secret app-secret -o yaml
apiVersion: v1
data:
DB_PASSWORD: czNjcjN0
DB_USER: YXBw
kind: Secret
metadata:
name: app-secret
type: Opaque
# Récupérer et décoder une clé
$ kubectl get secret app-secret -o jsonpath='{.data.DB_PASSWORD}' | base64 -d
s3cr3t
D’un point de vue sécurité, le base64 n’est pas un chiffrement. Si une personne a accès aux Secrets et dispose des droits nécessaires, elle peut en lire les valeurs. Cela peut faciliter une compromission plus large et une latéralisation dans le cluster.
Exemple : un Secret contient des identifiants administrateur d’une application web. Un utilisateur du cluster ayant l’accès et les droits nécessaires peut récupérer ces identifiants, pourra se connecter à l’application avec des privilèges d’administration et potentiellement agir en dehors de son périmètre prévu.
ConfigMaps
Un objet Kubernetes ConfigMap permet de séparer la configuration du code. La même image tourne en dev, préprod et prod avec des valeurs différentes. La configuration se met à jour sans reconstruire l’image et peut être partagée entre plusieurs Deployments.
Il est théoriquement possible d’écrire des valeurs de configuration directement dans un Deployment ou de les embarquer dans l’image du conteneur. Cela fonctionne, mais oblige à modifier le manifeste et à redéployer pour chaque changement, ou à reconstruire l’image. On duplique alors la configuration entre environnements et le risque de fuite augmente.
Exemple :
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
APP_MODE: "prod"
API_URL: "https://api.example.com"
Un pod peut alors lire ces valeurs comme variables d’environnement ou en les montant sous forme de fichiers.
Bien que ce soit une mauvaise pratique, il arrive que des valeurs sensibles se retrouvent dans un ConfigMap. Comme son contenu est stocké et renvoyé en clair par l’API, toute personne ou tout pod ayant accès à l’objet peut les lire.
Extrait pour récupérer une valeur :
$ kubectl get configmap app-config -o jsonpath='{.data.API_URL}'
https://api.example.com
D’un point de vue sécurité, il arrive que des données sensibles y soient stockées par erreur. Or, contrairement aux Secrets, les ConfigMaps ne sont pas encodés : leur contenu est visible en clair. De plus, les droits de lecture (RBAC) sur les ConfigMaps sont souvent plus larges. Un attaquant ayant accès à ces objets peut donc récupérer des identifiants ou tokens immédiatement exploitables, sans aucune étape de décodage.
PersistentVolumeClaim (PVC) et PersistentVolume (PV)
Un PersistentVolumeClaim (PVC) est une demande de stockage persistant et un PersistentVolume (PV) est le volume obtenu en réponse au PVC : c’est l’objet concret qui représente le stockage dans le cluster (le « disque »).
Concrètement, cela permet à un pod d’obtenir un espace disque monté dans le conteneur. Les données restent présentes même si le pod est recréé. Si plusieurs pods montent le même PersistentVolumeClaim (PVC), ils partagent les mêmes fichiers.
Quand un PersistentVolumeClaim (PVC) est supprimé, la liaison avec le PersistentVolume (PV) disparaît et le pod perd le volume. Le PV peut rester ou être supprimé selon son réglage.
Exemple :
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: web-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
Cette demande de stockage de 1 Go permet, par exemple, à une application web d’enregistrer des fichiers envoyés par les utilisateurs dans /data. Si le pod redémarre ou est recréé, ces fichiers restent présents, car le volume persiste indépendamment du pod. Sans stockage persistant, le pod écrirait dans un système de fichiers éphémère et toute donnée serait perdue à chaque recréation du pod.
Cet objet présente des risques de sécurité. Par exemple, un utilisateur disposant des droits nécessaires peut récupérer des données sensibles stockées dans un PersistentVolume (PV). Des PersistentVolume (PV) peuvent aussi rester présents dans le cluster après la suppression du PersistentVolumeClaim (PVC) si le nettoyage n’a pas été effectué ou si la politique de rétention les conserve.
D’un point de vue sécurité, l’accès aux données d’un PersistentVolume (PV) est un risque direct : un utilisateur ou un pod ayant les droits nécessaires sur le PersistentVolumeClaim (PVC) peut lire des données sensibles stockées par l'application. Plus grave encore, si le PersistentVolume (PV) est mal configuré, il devient possible de monter un répertoire critique du nœud de travail lui-même. Cela permet potentiellement à un attaquant d'examiner et de modifier les fichiers du système d'exploitation du nœud, menant à une compromission totale de la machine hôte et potentiellement du cluster.
Objets de gestion de droits (RBAC)
ServiceAccount, Role et RoleBinding
Un ServiceAccount (SA) est l’identité d’un pod quand il doit parler à l’API Kubernetes qui est dans le plan de contrôle. Il permet de donner des permissions précises à une application via RBAC (rôles et liaisons). Par défaut, si rien n’est précisé, un pod utilise un ServiceAccount par défaut, ce qui est une mauvaise pratique.
Exemple d’un manifeste d’un ServiceAccount :
apiVersion: v1
kind: ServiceAccount
metadata:
name: web-sa
À ce stade, ce ServiceAccount n’a aucun droit : il existe dans le cluster Kubernetes mais ne peut rien faire. Pour lui donner des permissions, on crée deux objets : un Role (les droits) et un RoleBinding (le lien entre le Role et le ServiceAccount).
Le Role définit les actions autorisées sur des ressources spécifiques :
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: web-read-config
rules:
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "list", "watch"]
Et le dernier objet RoleBinding va lier l’objet Role à l’objet ServiceAccount qui va alors récupérer ces droits.
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: web-read-config-binding
subjects:
kind: ServiceAccount
name: web-sa
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: web-read-config
L’avantage de ce fonctionnement est qu’il est alors possible de lier plusieurs objets ServiceAccount à un même Role et donc plusieurs ServiceAccount peuvent hériter du même droit. Cela évite la multiplication des objets.
⚠️ Attention : ces objets ne sont pas déclarés à l’échelle du cluster, mais au sein d’un sous-espace du cluster appelé namespace. L’explication de ce qu’est un namespace sera donnée dans le deuxième article, pas dans celui-ci. Afin de mieux comprendre ce fonctionnement, des exemples simples sont détaillés dans la suite de cet article.
ClusterRole et ClusterRoleBinding
Comme expliqué dans la partie précédente, les objets Kubernetes Role et RoleBinding ne sont pas définis à l’échelle du cluster, mais dans un sous-espace appelé namespace. À l’inverse, il existe des objets équivalents, avec la même logique, portés au niveau du cluster : ClusterRole et ClusterRoleBinding.
L’objectif est de définir des permissions qui s’appliquent à tous les sous-espaces (namespace) et de permettre l’administration du cluster sans dupliquer les règles partout. Par exemple, lier un sujet au ClusterRole cluster-admin via un ClusterRoleBinding accorde tous les droits sur l’API du cluster.
Exemple analogique simple
Afin d’expliquer au mieux le fonctionnement des droits au sein d’un cluster Kubernetes, voici une analogie simple en lien avec le milieu de l’entreprise :
Dans cette analogie, chaque département de l’entreprise représente un namespace.
Dans le département Marketing (Namespace), on crée le droit « obtenir un café gratuit » (Role). Alice (ServiceAccount) et Bob (ServiceAccount) reçoivent chacun une carte (RoleBinding) qui relie ce droit (Role) à leur identité. Leur carte est valide uniquement dans le département Marketing (Namespace).
Dans le département Finance (Namespace), Camille (ServiceAccount) possède une carte globale (ClusterRoleBinding) vers le droit « café gratuit entreprise » (ClusterRole). Elle peut utiliser tous les distributeurs de l’entreprise, y compris ceux d’autres départements (Namespaces).
Remarque : une carte de département (RoleBinding) peut aussi pointer vers un droit global (ClusterRole) ; dans ce cas, le droit reste limité au département (Namespace) où se trouve la carte (RoleBinding).

Aspect sécurité
Ces objets Kubernetes sont essentiels à connaître et à maîtriser lors d’un pentest de cluster. Comme en pentest Active Directory, l’objectif est d’escalader ses privilèges jusqu’au contrôle total. Dans AD, cela correspond au groupe « Administrateurs du domaine ». Dans Kubernetes, cela revient à obtenir le ClusterRole cluster-admin, rattaché via un ClusterRoleBinding. Ce niveau donne tous les droits sur l’API du cluster. C’est le Graal 🏆
Conclusion et ouverture
Dans ce premier article, on a présenté les bases : nœuds, plan de contrôle, objets clés (Pods, Deployments, Secrets, ConfigMaps, PVC/PV) et les éléments d’identité et de droits avec les ServiceAccounts et le RBAC.
La suite ira plus loin sur la sécurité d’un cluster Kubernetes. On abordera le cloisonnement, qu’il soit logique (namespaces) ou réseau (communications entre pods et segments), en expliquant leur fonctionnement et les principaux points de sécurité associés : isolation, contrôle des accès et politiques de communication.